- 이건재 교수팀, 유연 압전 음성 센서로 초고감도 인공지능 음성인식 및 보안기술 구현
- 스마트폰, 인공지능 스피커에 탑재해 제품화 성공, 대량생산 상용화 공정 완성 단계

▲KAIST 신소재공학과 이건재 교수
KAIST(총장 신성철)는 신소재공학과 이건재 교수와 왕희승 박사팀이 *공진형 유연 압전 음성 센서를 개발해 정확도가 높은 초고감도의 인공지능 기반 화자(話者) 식별 및 음성 보안기술을 구현했으며, 이를 스마트폰과 인공지능 스피커에 탑재해 제품화하는 데도 성공했다고 15일 밝혔다.
☞ 공진형 압전 음성 센서: 공진이란 특정 주파수 영역에서 센서가 큰 진폭으로 진동하는 현상을 말하며, 압전이란 압력을 가했을 때, 전기적인 신호가 자발적으로 생성되는 현상을 말한다. 음성에 의해 센서의 막이 진동하게 될 때, 공진 현상이 일어나 민감도 높은 전압 신호를 얻을 수 있다.
인간이 먼 거리의 소리를 인식하는 방법은 달팽이관에 있는 사다리꼴 막이 가청주파수 대역에서 수많은 공진 현상을 발생시키며 소리를 증폭하는 원리에 있다. 연구진은 이러한 원리의 효과를 극대화하기 위해 매우 얇은 유연 압전 막을 사용해 인간의 귀를 모사했고, 여러 공진 채널을 구현해 소리를 초고감도로 식별할 수 있는 공진형 음성 센서를 제작했다.
이건재 교수팀은 2018년도에 세계 최초로 공진형 유연 압전 음성 센서 개념을 제시한 데 이어, 이번 연구에서는 센서 구조에 따른 공진, 주파수, 압전 막의 역할 등을 이론적으로 밝히고 크기를 매우 소형화함과 동시에 성능이 향상된 음성 센서를 개발했다.
유연 압전 음성 센서는 원거리에서 스마트 기기들을 정확하게 제어하는 미래 사물인터넷 기술과 음성을 암호화하는 보안기술을 연결함으로써 소비자 맞춤형 서비스 제공에 크게 이바지할 것으로 전망된다.
생체 모사된 공진형 음성 센서는 신호 대 잡음비(Signal to noise ratio, SNR)가 우수해 음성인식 기능이 뛰어나고 다수 채널을 보유하기 때문에, 인공지능 음성 서비스에 적은 데이터양으로도 화자 식별 정확도를 높이는 강점이 있다.
연구팀의 음성 센서는 같은 조건에서 정전용량형 상용 마이크로폰과 성능 비교를 진행한 결과, 음성 분석 및 화자 식별에 있어 인식률을 크게 높였고 조건에 따라 오류율을 60%에서 95%까지 줄일 수 있었다.
연구팀이 개발한 시제품은 이 교수가 교원 창업한 기업인 ㈜프로닉스 社를 통해 2020년 세계 가전박람회(CES)에서 공개된 바 있으며, 현재 해당 기술은 완성도 높은 인공지능 음성 기술을 시연하며 ㈜프로닉스 미국 지사를 통해 실리콘밸리의 유수 IT 기업들과 협업도 추진하고 있다.
이건재 교수는 "이번에 제품화된 모바일 음성 센서는 높은 민감도를 보유하면서도 크기를 획기적으로 줄였기 때문에 미래 인공지능기술을 구동하는 핵심 센서로 적용할 수 있다ˮ며 "현재 대량생산 상용화 공정도 완성 단계에 있어 실생활에 곧 적용될 수 있을 것이다”라고 말했다.
이번 연구는 한국연구재단의 휴먼플러스 인공지능 센서 센터의 지원을 받아 수행됐으며, 국제 학술지 `사이언스 어드밴시스(Science Advances)'에 2월 12일 字 게재됐다.
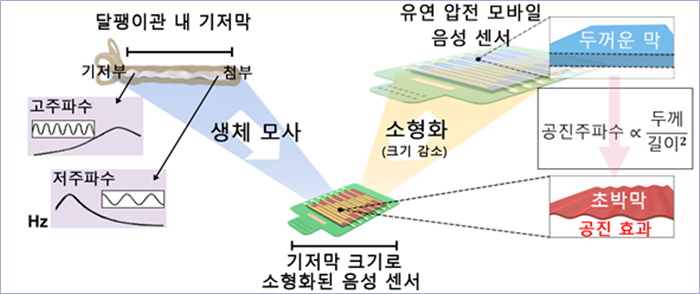
그림 1. 달팽이관 내 기저막을 모사한 모바일 압전 음성 센서의 원리
인간 달팽이관 내 기저막은 길이 30mm의 작은 크기를 가지며 공진 현상에 의해 소리를 인식하는데 이는 수 마이크로미터 (미터의 백만분의 일)의 매우 얇은 두께를 갖기 때문이다. 이 원리를 모사하여 초박형 압전 막 및 폴리머 기판을 활용하여 높은 민감도의 모바일 음성 센서를 제작하였다.
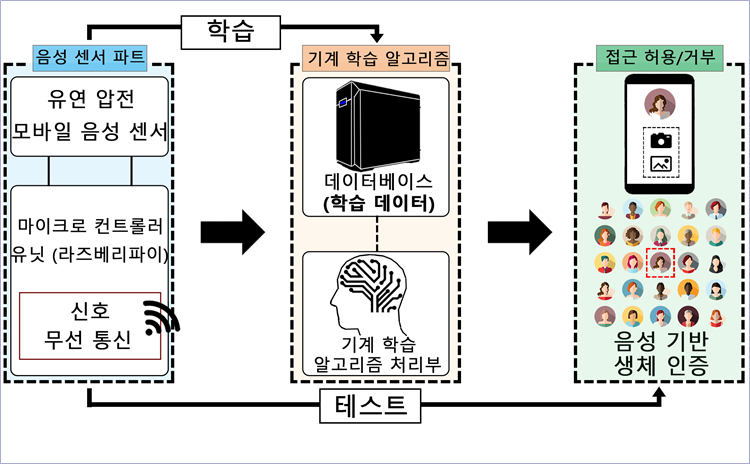
그림 2. 인공지능을 통한 화자 식별 개략도
모바일 음성 센서를 상용 전자 회로와 시스템적으로 통합한 후 무선 통신으로 서버에 음성 데이터를 송신하여 신호를 분석 및 학습한다. 이후 새로운 음성 데이터가 입력되었을 시 알고리즘을 기반으로 기존 학습된 화자의 특성과 얼마나 유사한지 계산하여 화자를 식별한다.

그림 3. 스마트폰 및 인공지능 스피커에 탑재된 유연 압전 음성 센서
스마트폰에 탑재되어 화자 식별 데모 서비스를 시현하고 있는 사진 (첫 번째)과 상용 전자회로 (두 번째)와 통합되어 함께 AI 스피커에 탑재된 후 녹음을 진행 중인 사진 (세 번째)이다.
□ 용어 설명
1. 정전용량형 상용 마이크로폰 (Commercial Condenser Microphone)
○ 진동에 의해 캐패시터의 두 도체막 간 거리에 변화가 생길 때 정전용량 차이가 발생하는 것을 이용해 음성 신호를 측정하는 마이크로폰을 말한다.
2. 공진형 압전 음성 센서 (Resonant Piezoelectric Acoustic Sensor)
○ 공진이란 특정 주파수 영역에서 센서가 큰 진폭으로 진동하는 현상을 말하며 압전이란 압력을 가했을 때 전기적인 신호가 자발적으로 생성되는 현상을 일컫는다. 음성 센서의 공진 주파수를 사람 목소리 대역으로 설계하면 음성에 의해 센서의 막이 진동하게 될 때 공진 현상이 일어나 민감도 높은 전압 신호를 얻을 수 있다.
3. 인공지능 (Artificial Intelligence)
○ 인간의 학습, 추론, 지각, 논리 전개, 이해 능력 등을 인공적으로 구현한 컴퓨터 프로그램 또는 시스템으로써 기계가 경험 데이터를 통해 특정 분야에 대한 지식을 학습하고 새로운 입력 내용에 반응하여 스스로 과제를 수행하여 결과물을 제시한다.
4. 신호 대 잡음 비 (Signal to noise ratio)
○ 신호에 영향을 주는 주변 잡음 세기에 대한 신호 세기의 비율이다. 비율이 높을수록 배경 잡음이 덜하기 때문에 높은 신호 대 잡음 비를 갖는 센서를 개발하면 원거리 인식, 민감한 소리 감지 등이 가능하다.
5. 화자(話者) 식별 기술
○ 화자란 소리를 내는 사람이라는 뜻으로, 화자 식별 기술은 기계가 사람의 목소리를 학습하여 분류함으로써 추후 임의의 화자가 말을 했을 때 데이터베이스에 저장되어 있는지 아닌지 확인하여 추가적인 기능을 제공한다.










